By Justin Esarey
A few weeks ago, Jason Mitchell wrote a piece entitled “On the emptiness of failed replications.” Mitchell is a professor in Harvard University’s department of Psychology studying “the cognitive processes that support inferences about the psychological states of other people and introspective awareness of the self.” In practice, this means his lab spends a lot of time doing experiments with fMRI machines.
It is worth saying at the outset that I don’t agree with Mitchell’s core claim: unlike him, I believe that failed replications can have a great deal of scientific value. However, I believe that there is a grain of truth in his argument that we should consider. Namely, I think that failed replications should be thought about in the same way that we think about the initial successful experiment: skeptically. A positive result is not proof of success, and a failed replication is not proof of failure; the interpretation of both must be uncertain and ambiguous at first. Unfortunately, I have observed that most of us (even highly trained scientists) find it hard to make that kind of uncertainty a part of our everyday thinking and communicating.
The thesis of Mitchell’s argument is summarized in his opening paragraph:
Recent hand-wringing over failed replications in social psychology is largely pointless, because unsuccessful experiments have no meaningful scientific value. Because experiments can be undermined by a vast number of practical mistakes, the likeliest explanation for any failed replication will always be that the replicator bungled something along the way. Unless direct replications are conducted by flawless experimenters, nothing interesting can be learned from them.
Why do I believe that Mitchell’s claim about the scientific value of failed replication is wrong? Lots of other statisticians and researchers have explained why very clearly, so I will just link to their work and present a brief sketch of two points:
- Failed replications have proved extremely informative in resolving past scientific controversies.
- Sampling variation and statistical noise cannot be definitively excluded as explanations for a “successful experiment” without a very large sample and/or replication.
First, the consistent failure to replicate an initial experiment has often proven informative about what we could learn from that initial experiment (often, very little). Consider as one example the Fleischmann–Pons experiment apparently demonstrating cold fusion. Taken at face value, this experiment would seem to change our theoretical understanding about how nuclear fusion works. It would also seem to necessitate the undertaking of intense scientific and engineering study of the technique to improve it for commercial and scientific use. But if we add the fact that no other scientists could ever make this experiment work, despite sustained effort by multiple teams, then the conclusion is much different and much simpler: Flesichmann and Pons’ experiment was flawed.
Second, and relatedly, Mitchell seems to admit multiple explanations for a failed replication (error, bias, imperfect procedure) but only one explanation for the initial affirmative result (the experiment produced the observed relationship):
To put a fine point on this: if a replication effort were to be capable of identifying empirically questionable results, it would have to employ flawless experimenters. Otherwise, how do we identify replications that fail simply because of undetected experimenter error? When an experiment succeeds, we can celebrate that the phenomenon survived these all-too-frequent shortcomings. But when an experiment fails, we can only wallow in uncertainty about whether a phenomenon simply does not exist or, rather, whether we were just a bit too human that time around.
The point of conducting statistical significance testing is to exclude another explanation for a successful experiment: random noise and/or sampling variation produced an apparent result where none in fact exists. There is also some evidence to suggest that researchers consciously or unconsciously make choices in their research that improve the possibility of passing a statistical significance test under the null (so-called “p-hacking”).
Perhaps Mitchell believes that passing a statistical significance test and peer review definitively rules out alternative explanations for an affirmative result. Unfortunately, that isn’t necessarily the case. In joint work with Ahra Wu I find evidence that, even under ideal conditions (with no p-hacking, misspecification bias, etc.), statistical significance testing cannot prevent excess false positives from permeating the published literature. The reason is that, if most research projects are ultimately chasing blind alleys, the filter imposed by significance testing is not discriminating enough to prevent many false positives from being published. The result is one of the forms of “publication bias.”
Yet despite all this, I think there is a kernel of insight in Mitchell’s argument. I think the recent interest in replication is part of a justifiably greater skepticism that we are applying to new discoveries. But we should also apply that greater skepticism to isolated reports of failed replication–and for many of the same reasons. Allow me to give one example.
One source of publication bias is the so-called “file drawer problem,” whereby studies of some phenomenon that produce null results never get published (or even submitted); thus, false positive results (that do get published) are never placed into their proper context. But this phenomenon is driven by the fact that evidence in favor of new theories is considered more scientifically important than evidence against theories without a wide following. But if concern about false positives in the literature becomes widespread, then replications that contradict a published result may become more scientifically noteworthy than replications that confirm that result. Thus, we may become primed to see (and publish) falsifying results and to ignore confirmatory results. The problem is the same as the file drawer problem, but in reverse.
Even if we do our best to publish and take note of all results, we can reasonably expect many replications to be false negatives. To demonstrate this, I’ve created a simulation of the publication/replication process. First, a true relationship (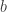





However, I also allow for the possibility of “biased” replications that favor the null; this is represented by moving the 
The code to execute this simulation in R is shown here:
set.seed(123456)rm(list=ls())se.b# std. error of est. betareps# number of MC runsbias# degree of replicator null biaspr.null# prior Pr(null hypothesis)# where to store true, est., and replicated resultsb.storematrix(data=NA, nrow=reps, ncol=3)# where to store significance of est. and replicated betassig.storematrix(data=NA, nrow=reps, ncol=2)pbtxtProgressBar(init=0, min=1, max=reps, style=3)for(iin1:reps){setTxtProgressBar(pb, value=i)# draw the true value of betaif(runif(1)b}else{bsign(runif(1, min=-1, max=1))*runif(1, min=1, max=2)}# simulate an estimated betab.estrnorm(1, mean=0, sd=se.b)# calculate if est. beta is statistically significantif(abs(b.est / se.b) >= 1.96){sig.initelse{sig.init# if the est. beta is stat. sig., replicateif( sig.init == 1 ){# draw another beta, with replicator biasb.reprnorm(1, mean=0, sd=se.b) -sign(b)*bias# check if replicated beta is stat. sig.if(abs(b.rep / se.b) >= 1.96){sig.repelse{sig.rep}else{b.repNA; sig.repNA}# store the resultsb.store[i, ]c(b, b.est, b.rep)sig.store[i, ]c(sig.init, sig.rep)}close(pb)# plot estimated vs. replicated resultsplot(b.store[,2], b.store[,3], xlab ="initial estimated beta", ylab ="replicated beta")abline(0,1)abline(h = 1.96*se.b, lty=2)abline(h = -1.96*se.b, lty=2)dev.copy2pdf(file="replication-result.pdf")# false replication failure rate1 -sum(sig.store[,2], na.rm=T)/sum(is.na(sig.store[,2])==F)
So: I believe that it is important not to replace one suboptimal regime (privileging statistically significant and surprising findings) with another (privileging replications that appear to refute a prominent theory). This is why many of the people advocating replication are in favor of something like a results-blind publication regime, wherein no filter is imposed on the publication process. As Ahra and I point out, that idea has its own problems (e.g., it might creates an enormous unpaid burden on reviewers, and might also force scientists to process an enormous amount of low-value information on null results).What do we find? In this scenario, about 30% of replicated results are false negatives; that is, the replication study finds no effect where an effect actually exists. Furthermore, these excess false negatives cannot be attributed to small relationships that cannot be reliably detected in an underpowered study; this is why I extracted the values of
In summary: I think the lesson to draw from the publication bias literature, Mitchell’s essay, and the simulation result above is: the prudent course is to be skeptical of any isolated result until it has been vetted multiple times and in multiple contexts. Unexpected and statistically significant relationships discovered in new research should be treated as promising leads, not settled conclusions. Statistical evidence against a conclusion should be treated as reason for doubt, but not a debunking.