By Anthony Fowler
The refrain is ubiquitous in seminars, workshops, and the discussion sections of quantitative studies. An audience member or reviewer might raise one of the following objections:
- The purported effect/mechanism seems implausible.
- It seems unlikely that your design could detect the effect/mechanism of interest.
- Your estimates are likely biased toward zero.
The common, often enthusiastic retorts are the subject of this essay:
- But shouldn’t that work against me?
- Shouldn’t that make it harder for me to detect an effect?
- Doesn’t that make it all the more likely that I have, in fact, detected a genuine effect?
- Don’t my statistically significant results negate your concern?
In this note, I explain why these retorts are typically not satisfying. As a preview, the answers to these four questions are, respectively, you’re a scientist not a lawyer, yes, no, and no.
For convenience, I’ll refer to the author’s line of argument as the work-against-me defense. The author believes that the surprisingness of her results should make her audience, if anything, even more persuaded by the analysis. The problems with this argument are two-fold. First, because we’re scholars and not activists, we often care about biases in either direction. Underestimating a substantively significant phenomenon could be just as problematic as overestimating a substantively trivial phenomenon. Second, even if we don’t care about substantive effect sizes, Bayes’ rule tells us that more surprising results are also more likely to be wrong. All else equal, the lower the power of the study or the lower our prior beliefs, the lower our posterior beliefs should be conditional upon detecting a positive result. Consistent with the author’s intuition, low power and low prior beliefs make it harder to obtain a positive estimate, but inconsistent with the author’s intuition, this also means that conditional upon obtaining a positive estimate, it’s more likely that we’ve obtained a false positive.
We Often Care About Biases in Either Direction
The goals of social science are many and complex. Among other things, we want to better understand how the social and political world works, and when possible, we want to help people make better decisions and contribute to policy debates. Our ability to do those things would be quite limited if we could only produce a list of binary results: e.g., prices affect choices, electoral institutions influence policy outcomes, legislative institutions can cause gridlock, and legal institutions can enhance economic growth.
One setting in which quantitative estimates from social scientific studies are particularly relevant is the vaunted cost-benefit analysis. The CBO, EPA, FDA, or UN (pick your favorite acronym) might look to academic studies to figure out if a proposed policy’s benefits are worth the costs. It’s fairly obvious that in this setting, we would like unbiased estimates of the costs and the benefits. And generally speaking, there’s no compelling argument that underestimating a quantity of interest is somehow better than overestimating it. Of course, there could be a particular situation where the costs are well understood and we have a biased estimate of the benefits that exceeds the costs. This would be a situation in which the work-against-me defense might be persuasive (although this assumes there is no selective reporting, a topic to which I’ll return). But there would be still many other situations in which the work-against-me defense would be counterproductive.
Even when we’re not engaging in cost-benefit analyses, we often care about the substantive magnitude of our estimates. Presumably, we don’t just want to know, for example, whether political polarization influences inequality, whether campaign contributions distort the behavior of elected officials, whether the loss of health insurance increases emergency room utilization, or whether taste-based discrimination influences hiring decisions. We want to know how much. Are these big problems or small problems?
Bayes’ Rule and False Positive Results
Suppose that we don’t care about substantive magnitudes. We just want to know if an effect exists or not. Is the work-against-me defense compelling in this case? The answer is still no. Let’s see why.
My concerns about the work-against-me defense are closely related to concerns about selective reporting and publication bias. Authors typically only use the work-against-me defense when they have obtained a non-zero result, and they likely would never have reported the result if it were null. After all, the work-against-me defense wouldn’t make much sense if the result were null (although as we’ll see, it rarely makes sense). As we already know, selective reporting means that many of our published results are false positives or overestimates (e.g., see Ioannidis 2005; Simmons, Nelson, and Simonsohn 2011), and as it turns out, things that work against the author’s purported hypothesis can exacerbate the extent of this problem.
Since we’re now considering situations in which we don’t care about effect sizes, let’s assume that effects and estimates are binary. A purported effect is either genuine or not, and our statistical test either detects it or not. When we see a result, we’d like to know the likelihood that the purported effect is genuine. Since the work-against-me defense is only ever used when a researcher has detected an effect, let’s think about our posterior beliefs conditional upon obtaining a positive result:
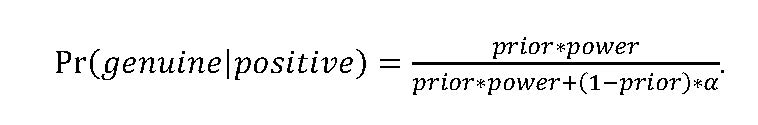
Conditional upon positively detecting an effect, the probability that the effect is genuine is a function of our prior beliefs (our ex-ante beliefs about the likelihood the effect is genuine before seeing this estimate), the power of the study (the probability of a positive result if the effect is genuine), and the probability of a positive result if the effect is not genuine, which I refer to as α for convenience.
The equation above is just a simple application of Bayes’ rule. It tells us that, all else equal, we’re more confident that an estimated effect is genuine when (1) the prior is higher, (2) the power is higher, and (3) α is lower. All of this sounds obvious, although the implications for the work-against-me defense may not be.
How does the exchange between the seminar critic and the author at the outset of this essay relate to the equation? The purported mechanism seems implausible is just another way of saying that one’s prior is low. Your design is unlikely to detect this effect is another way of saying the power is low. Conditional upon having obtained a positive result, low power and/or low priors make it less likely that the estimated effect is genuine.
Your estimates are likely biased toward zero is a trickier case. How can we think about a bias toward zero in the context of this discussion of Bayes’ rule? A bias toward zero clearly reduces power, making an analyst less likely to reject the null if the effect of interest is genuine. However, some biases toward zero also reduce α, making an analyst less likely to reject the null if the effect of interest is not genuine. Suppose we’re conducting a one-sided hypothesis test for a purportedly positive effect. Attenuation bias (perhaps resulting from measurement error) lowers power without lowering α, so the presence of attenuation bias has an unambiguously negative effect on our posterior beliefs. Now imagine a systematic bias that lowers all estimates without increasing noise (e.g., omitted variables bias with a known negative sign). This lowers power but it also lowers α. So this kind of bias has an ambiguous effect on our posterior beliefs conditional on a positive result. Reducing power decreases our beliefs that the result is genuine while reducing α increases our beliefs. And it will likely be hard to know which effect dominates. But suffice it to say that a bias toward zero either has negative or ambiguous implications for the credibility of the result, meaning that the work-against-me defense is misguided even in this context.
Low power and low priors make it less likely that the author will detect an effect. That’s where the author’s intuition is right. Given the critic’s concerns about the prior and/or the power, we’re surprised that the author obtained a positive result. But seeing a positive result doesn’t negate these concerns. Rather, these concerns mean that conditional upon detecting an effect, the result is more likely to be a false positive. Presumably, we don’t want to reward researchers for being lucky and obtaining surprising estimates. We want to publish studies with reliable estimates (i.e., our posteriors are high) or those that meaningfully shift our beliefs (i.e., our posteriors are far from our priors). When the prior beliefs and/or power are really low, then our posterior beliefs should be low as well.
Discussion
The work-against-me defense is rarely if ever persuasive. In cases where we care about the substantive magnitude of the effect of interest, we typically care about biases in either direction. And in cases where we don’t care about the substantive magnitude but we just want to know whether an effect or mechanism exists, low power and/or a low prior make it more likely that a reported result is a false positive.
Loken and Gelman (2017) conduct simulations that make the same point made here regarding attenuation bias. What I call the work-against-me defense, they refer to as “the fallacy of assuming that that which does not kill statistical significance makes it stronger” (p. 584). However, I believe it’s illustrative to see the same points made using only Bayes’ rule and to see that all forms of the work-against-me defense are unpersuasive, whether in regard to low power, biases toward zero, or low priors.
The problem with the work-against-me defense is likely not intuitive for most of us. Loken and Gelman also use an analogy that is helpful for thinking about why our intuitions can lead us astray. “If you learned that a friend had run a mile in 5 minutes, you would be respectful; if you learned that she had done it while carrying a heavy backpack, you would be awed” (p. 584). So why does the same intuition not work in the context of scientific studies? It has to do with both noise and selective reporting. If you suspected that your friend’s mile time was measured with significant error and that you would have only learned about her performance if her time was 5 minutes or less, learning about the heavy backpack should lead you to put more weight on the possibility that it was measurement error rather than your friend’s running ability that explains this seemingly impressive time. In light of measurement error or noise, the effect of learning about the backpack on your inference about your friend’s running ability is ambiguous at best.
Where does this leave us? Careful researchers should think about biases in either direction, they should think about their priors, and they should think about the power of their study. If there’s little reason to suspect a genuine effect or if the test isn’t likely to distinguish genuine effects from null effects, then there’s little point in conducting the test. Even if the test favors the hypothesis, it will likely be a false positive. And referees and seminar attendees should probably ask these cranky questions even more often, assuming their concerns are well justified.
I suspect a common time to invoke the work-against-me defense is in the planning stages of a research project. An eager, career-oriented researcher might anticipate a number of objections to their study. But they reassure themselves, “But that should work against me, making it all the more impressive if I find the result I’m hoping for. I might as well run the test on the off chance that I get a positive result.” Bayes’ rule tells us why this is a bad idea. In general, we probably shouldn’t be running tests that we know we’d only report if they were statistically significant. And the credibility of our results is compromised when our prior or power is low.
For all of these reasons, let’s dispense with the work-against-me defense.
References
Ioannidis, John P.A. 2005. Why Most Published Research Findings Are False. PLOS Medicine 2(8):696-701.
Loken, Eric and Andrew Gelman. 2017. Measurement Error and the Replication Crisis: The Assumption that Measurement Error Always Reduces Effect Sizes is False. Science 355(6325):584-585.
Simmons, Joseph P., Leif D. Nelson, and Uri Simonsohn. 2011. False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant. Psychological Science 22(11):1359-1366.