By Justin Esarey
[Update 12/2/2018 at 10:45 AM ET: A corrigendum to this piece has been published.]
Introduction
A large and interdisciplinary group of researchers recently proposed redefining the conventional threshold of statistical significance from p p false discovery rate, or the proportion of statistically significant findings that are null relationships (Benjamini and Hochberg 1995), is reduced by its implementation. Benjamin et al. (2017) explicitly disavow a requirement that results meet the stricter standard in order to be publishable, but in the past statistical significance has been used as a necessary condition for publication (T. D. Sterling 1959; T. Sterling, Rosenbaum, and Winkam 1995) and we must therefore anticipate that a redefinition of the threshold for significance may lead to a redefinition of standards for publishability.
As a method of screening empirical results for publishability, the conventional p power of the test to detect non-null relationships is harmed at the same time that the size of the test (i.e., its propensity to mistakenly reject a true null hypothesis) is reduced. The usual way of increasing the power of a study is to increase the sample size, N; given the fixed nature of historical time-series cross-sectional data sets and the limited budgets of those who use experimental methods, this means that many researchers may feel forced to accept less powerful studies and therefore have fewer opportunities to publish. Additionally, reducing the threshold for statistical significance can exacerbate publication bias, i.e., the extent to which the published literature exaggerates the magnitude of an relationship by publishing only the largest findings from the sampling distribution of a relationship (T. Sterling, Rosenbaum, and Winkam 1995; Scargle 2000; Schooler 2011; Esarey and Wu 2016).
Simply accepting lower power in exchange for a lower false discovery rate would increase the burden on the most vulnerable members of our community: assistant professors and graduate students, who must publish enough work in a short time frame to stay in the field. However, there is a way of maintaining adequate power using p K-many statistically independent tests are performed on pre-specified hypotheses that must be jointly confirmed in order to support a theory, the chance of simultaneously rejecting them all by chance is αK where p α is the critical condition for statistical significance in an individual test. As K increases, the α value for each individual study can fall and the overall power of the study often (though not always) increases. It is important that hypotheses be specified before data analysis and that failed predictions are reported; simply conducting many tests and reporting the statistically significant results creates a multiple comparison problem that inflates the false positive rate (Sidak 1967; Abdi 2007). Because it is usually more feasible to collect a greater depth of information about a fixed-size sample rather than to greatly expand the sample size, this version of the reform imposes fewer hardships on scientists at the beginning of their careers.
I do not think that an NHST with a lowered α is the best choice for adjudicating whether a result is statistically meaningful; approaches rooted in statistical decision theory and with explicit assessment of out-of-sample prediction have advantages that I consider decisive. However, if reducing α prompts us to design research stressing the simultaneous testing of multiple theoretical hypotheses, I believe this change would improve upon the status quo—even if passing this more selective significance test becomes a requirement for publication.
False discovery rates and the null hypothesis significance test
Based on the extant literature, I believe that requiring published results to pass a two-tailed NHST with α = 0.05 is at least partly responsible for the “replication crisis” now underway in the social and medical sciences (Wasserstein and Lazar 2016). I also anticipate that studies that can meet a lowered threshold for statistical significance will be more reproducible. In fact, I argued these two points in a recent paper (Esarey and Wu 2016). Figure 1 reproduces a relevant figure from that article; the y-axis in that figure is the false discovery rate (Benjamini and Hochberg 1995), or FDR, of a conventional NHST procedure with an α given by the value on the x-axis. Written very generically, the false discovery rate is:
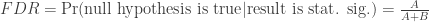
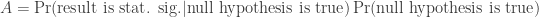

or, the proportion of statistically significant results (“discoveries”) that correspond to true null hypotheses. A is a function of the power of the test, Pr(stat. sig.|null hypothesis is true). B is a function of the size of the test, Pr(stat. sig.|null hypothesis is false). Both A and B are a function of the underlying proportion of null hypotheses being proposed by researchers, Pr(null hypothesis is true).
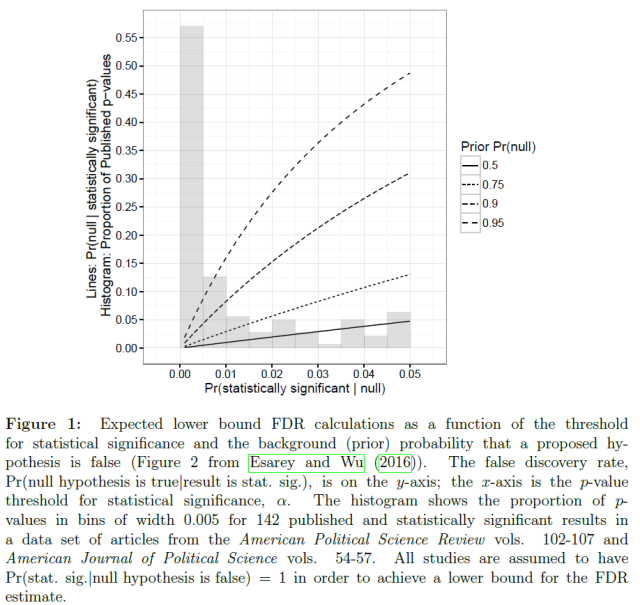
As Figure 1 shows, when Pr(null hypothesis is true) is large, there is a very disappointing FDR among results that pass a two-tailed NHST with α = 0.05. For example, when 90% of the hypotheses tested by researchers are false leads (i.e., Pr(null hypothesis is true)=0.9), we may expect nearly ≈30% of discoveries to be false when all studies have perfect power (i.e., Pr(stat. sig.|null hypothesis is false)=1). Two different studies applying disparate methods to data from the Open Science Collaboration’s replication project data (2015) have determined that approximately 90% of researcher hypotheses are false (V. E. Johnson et al. 2017; Esarey and Liu 2017); consequently, an FDR in the published literature of at least 30% is attributable to this mechanism. Even higher FDRs will result if studies have less than perfect power.
By contrast, Figure 1 also shows that setting α ≈ 0.005 would greatly reduce the false discovery rate, even when the proportion of null hypotheses posed by researchers is extremely high. For example, if 90% of hypotheses proposed by researchers are false, the lower bound FDR in the published literature among studies meeting the higher standard would be about 5%. Although non-null results are not always perfectly replicable in underpowered studies (and null results have a small chance of being successfully replicated), a reduction in the FDR from ≈30% to ≈5% would almost certainty and drastically improve the replicability of published results.
The Pareto frontier of adjudicating statistically meaningful results
Despite this and other known weaknesses of the current NHST, it lies on or near a Pareto frontier of possible ways to classify results as “statistically meaningful” (one aspect of being suitable for publication). That is, it is challenging to propose a revision to the NHST that will bring improvements without also bringing new or worsened problems, some of which may disproportionately impact certain segments of the discipline. Consider some dimensions on which we might rate a statistical test procedure, the first few of which I have already discussed above:
-
the false discovery rate created by the procedure, itself a function of:
- the power of the procedure to detect non-zero relationships, and
- the size of the procedure, its probability of rejecting true null hypotheses;
- the degree of publication bias created by the procedure, i.e., the extent to which the published literature exaggerates the size of an effect by publishing only the largest findings from the sampling distribution of a relationship (T. Sterling, Rosenbaum, and Winkam 1995; Scargle 2000; Schooler 2011; Esarey and Wu 2016);
- the number of researcher assumptions needed to execute the procedure, a criterion related to the consistency of the standards implied by use of the test; and
- the complexity, or ease of use and interpretability, of the procedure.
It is hard to improve on the NHST in one of these dimensions without hurting performance in another area. In particular, lowering α from 0.05 to 0.005 would certainly lower the power of most researchers’ studies and might increase the publication bias in the literature.
Size/power tradeoffs of lowering α
Changing the α of the NHST from 0.05 to 0.005 is a textbook example of moving along a Pareto frontier because the size and the power of the test are in direct tension with one another. Because powerful research designs are more likely to produce publishable results when the null is false, maintaining adequate study power is especially critical to junior researchers who need publications in order to stay in the field and advance their careers. The size/power tradeoff is depicted in Figure 2.
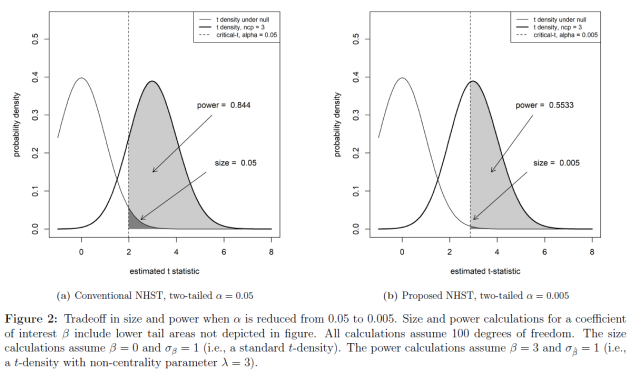
Figure 2 depicts two size and power analyses for a coefficient of interest β. I assume that 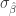
The most darkly shaded area under the right hand tail of the t-distribution under the null is the probability of incorrectly rejecting a true null hypothesis, α. As the figure shows, it is impossible to shrink α without simultaneously shrinking the lighter shaded area, where the lighter shading depicts the power of a hypothesis test to correctly reject a false null hypothesis. This tradeoff can be more or less severe (depending on β and
Increased publication bias associated with lowered α
The size/power tradeoff is not the only compromise associated with lowering α: in some situations, decreased α can increase the publication bias associated with using statistical significance tests as a filter for publication. Of course, (Benjamin et al. 2017) explicitly disavow using an NHST with lowered α as a necessary condition for publication; they say that “results that would currently be called ‘significant’ but do not meet the new threshold should instead be called ‘suggestive’” (p. 5). However, given the fifty year history of of requiring results to be statistically significant to be publishable (T. D. Sterling 1959; T. Sterling, Rosenbaum, and Winkam 1995), we must anticipate that this pattern could continue into the future.
Consider Figure 3, which shows two perspectives on how decreased α might impact publication bias. The left panel (Figure 3a) shows the percentage difference in magnitude between a true coefficient β = 3 and the average statistically significant coefficient using an NHST with various values of α.2 The figure shows that decreased values of α increase the degree of publication bias; this occurs because stricter significance tests tend to reject only the largest estimates from a sampling distribution, as also shown in Figure 2. On the other hand, the right panel (Figure 3b) shows the percentage difference in magnitude from a true coefficient drawn from a spike-and-normal prior density of coefficients:

where there is a substantial (50%) chance of a null relationship being studied by a researcher; 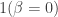
Adapting to a lowered α
If the proposal of (Benjamin et al. 2017) is simply to accept lowered power in exchange for lower false discovery rates, it is a difficult proposal to accept. First and foremost, assistant professors and graduate students must publish a lot of high-quality research in a short time frame and may be forced to leave the discipline if they cannot; higher standards that are an inconvenience to tenured faculty may be harmful to them unless standards for hiring and tenure adapt accordingly. In addition, even within a particular level of seniority, this reform may unlevel the playing field. Political scientists in areas that often observational data with essentially fixed N, such as International Relations, would be disproportionately affected by such a change: more historical data cannot be created in order to raise the power of a study. Among experimenters and survey researchers, those with smaller budgets would also be disproportionately affected: they cannot afford to simply buy larger samples to achieve the necessary power. Needless to say, the effect of this reform on the scientific ecosystem would be difficult to predict and not necessarily beneficial; at first glance, such a reform seems to benefit the most senior scholars and people at the wealthiest institutions.
However, I believe that acquiesence to lower power is not the only option. It may be difficult or impossible for researchers to collect larger N, but it is considerably easier for them to measure a larger number of variables of interest K from their extant samples. This creates the possibility that researchers can spend more time developing and enriching their theories so that these theories make multiple predictions. Testing these predictions jointly typically allows for much greater power than testing any single prediction alone, as long as any prediction is clearly laid out prior to analysis and all failed predictions are reported in order to avoid a multiple comparison problem (Sidak 1967; Abdi 2007); predictions must be specified in advance and failed predictions must be reported because simply testing numerous hypotheses and reporting any that were confirmed tends to generate an excess of false positive results.
When K-many statistically independent hypothesis tests are performed using a significance threshold of α and all must be passed in order to confirm a theory,4 the chance of simultaneously rejecting them all by chance is 
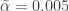
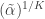
When will conducting a joint test of multiple hypotheses yield greater power than conducting a single test? If two hypothesis tests are statistically independent6 and conducted as part of a joint study, this will occur when:
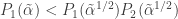
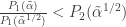
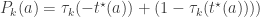
Here, τk is the non-central cumulative t-density corresponding to the sampling distribution of βk, k ∈ {1, 2}; I presume that k is sorted so that tests are in descending order of power. t⋆(a) is the positive critical t−statistic needed to create a single two-tailed hypothesis test of size a. The left hand side of equation (1) is the power of the single hypothesis test with the greatest power; the right hand side of equation (1) is the power of the joint test of two hypotheses. As equation (2) shows, the power of the joint test is larger when the proportional change in power for the test of β1 is less than the power for the test of β2. Whether this condition is met depends on many factors, including the magnitude and variability of β1 and β2.
To illustrate the potential for power gains, I numerically calculated the power of joint tests with size 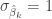
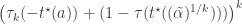
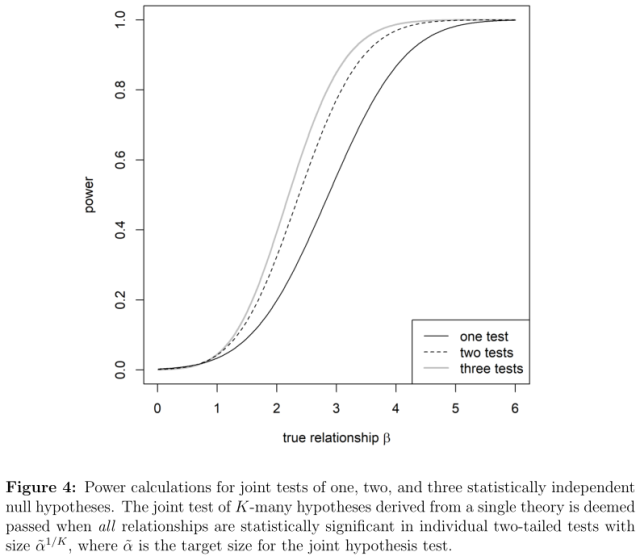
Figure 4 shows that joint hypothesis testing creates substantial gains in power over single hypothesis testing for most values of β. There is a small amount of power loss near the tails (where β ≈ 0 and β ≈ 6), but this is negligible.
Conclusion: the NHST with lowered α is an improvement, if we enrich our theories
There are reasons to be skeptical of the Benjamin et al. (2017) proposal to move the NHST threshold for statistical significance from α = 0.05 to α = 0.005. First, there is substantial potential for adverse effects on the scientific ecosystem: the proposal seems to advantage senior scholars at the most prominent institutions in fields that do not rely on fixed-N observational data. Second, the NHST with a reduced α is not my ideal approach to adjudicating which results are statistically meaningful; I believe it is more advantageous for political scientists to adopt a statistical decision theory-oriented approach to inference7 and give greater emphasis to cross-validation and out-of-sample prediction.
However, based on the evidence presented here and in related work, I believe that moving the threshold for statistical significance from α = 0.05 to α = 0.005 would benefit political science if we adapt to this reform by developing richer, more robust theories that admit multiple predictions. Such a reform would reduce the false discovery rate without reducing power or unduly disadvantaging underfunded scholars or subfields that rely on historical observational data, even if meeting the stricter standard for significance became a necessary condition for publication. It would also force us to focus on improving our body of theory; our extant theories lead us to propose hypotheses that are wrong as much as 90% of the time (V. E. Johnson et al. 2017; Esarey and Liu 2017). Software that automates the calculation of appropriate critical t-statistics for correlated joint hypothesis tests would make it easier for substantive researchers to make this change, and ought to be developed in future work. This software has already been created for joint tests involving interaction terms in generalized linear models by Esarey and Sumner (2017), but the procedure needs to be adapted for the more general case of any type of joint hypothesis test.
References
Abdi, Herve. 2007. “The Bonferonni and Sidak Corrections for Multiple Comparisons.” In Encyclopedia of Measurement and Statistics, edited by Neil Salkind. Thousand Oaks, CA: Sage. URL: https://goo.gl/EgNhQQ accessed 8/5/2017.
Benjamin, Daniel J., James O. Berger, Magnus Johannesson, Brian A. Nosek, E. J. Wagenmakers, Richard Berk, Kenneth A. Bollen, et al. 2017. “Redefine Statistical Significance.” Nature Human Behavior Forthcoming: 1–18. URL: https://osf.io/preprints/psyarxiv/mky9j/ accessed 7/31/2017.
Benjamini, Y., and Y. Hochberg. 1995. “Controlling the false discovery rate: a practical and powerful approach to multiple testing.” Journal of the Royal Statistical Society. Series B (Methodological) 57 (1). JSTOR: 289–300. URL: http://www.jstor.org/stable/10.2307/2346101.
Esarey, Justin, and Nathan Danneman. 2015. “A Quantitative Method for Substantive Robustness Assessment.” Political Science Research and Methods 3 (1). Cambridge University Press: 95–111.
Esarey, Justin, and Vera Liu. 2017. “A Prospective Test for Replicability and a Retrospective Analysis of Theoretical Prediction Strength in the Social Sciences.” Poster presented at the 2017 Texas Methods Meeting at the University of Houston. URL: http://jee3.web.rice.edu/replicability-package-poster.pdf accessed 8/1/2017.
Esarey, Justin, and Jane Lawrence Sumner. 2017. “Marginal Effects in Interaction Models: Determining and Controlling the False Positive Rate.” Comparative Political Studies forthcoming: 1–39. URL: http://jee3.web.rice.edu/interaction-overconfidence.pdf accessed 8/5/2017.
Esarey, Justin, and Ahra Wu. 2016. “Measuring the Effects of Publication Bias in Political Science.” Research & Politics 3 (3). SAGE Publications Sage UK: London, England: 1–9. URL: https://doi.org/10.1177/2053168016665856 accessed 8/1/2017.
Johnson, Valen E. 2013. “Revised Standards for Statistical Evidence.” Proceedings of the National Academy of Sciences 110 (48). National Acad Sciences: 19313–7.
Johnson, Valen E, Richard D. Payne, Tianying Wang, Alex Asher, and Soutrik Mandal. 2017. “On the Reproducibility of Psychological Science.” Journal of the American Statistical Association 112 (517). Taylor & Francis: 1–10.
Klein, Richard A., Kate A. Ratliff, Michelangelo Vianello, Reginald B. Adams, Stepan Bahnik, Michael J. Bernstein, Konrad Bocian, et al. 2014. “Investigating Variation in Replicability.” Social Psychology 45 (3): 142–52. doi:10.1027/1864-9335/a000178.
Open Science Collaboration. 2015. “Estimating the Reproducibility of Psychological Science.” Science 349 (6251): aac4716. doi:10.1126/science.aac4716.
Scargle, Jeffrey D. 2000. “Publication Bias: The ‘File-Drawer’ Problem in Scientific Inference.” Journal of Scientific Exploration 14: 91–106.
Schooler, Jonathan. 2011. “Unpublished Results Hide the Decline Effect.” Nature 470: 437.
Sidak, Zbynek. 1967. “Rectangular confidence regions for the means of multivariate normal distributions.” Journal of the American Statistical Association 62 (318): 626–33.
Sterling, T.D., W. L. Rosenbaum, and J. J. Winkam. 1995. “Publication Decisions Revisited: The Effect of the Outcome of Statistical Tests on the Decision to Publish and Vice Versa.” The American Statistician 49: 108–12.
Sterling, Theodore D. 1959. “Publication Decisions and Their Possible Effects on Inferences Drawn from Tests of Significance—or Vice Versa.” Journal of the American Statistical Association 54 (285): 30–34. doi:10.1080/01621459.1959.10501497.
Wasserstein, Ronald L., and Nicole A. Lazar. 2016. “The Asa’s Statement on P-Values: Context, Process, and Purpose.” The American Statistician 70 (2): 129–33. URL: http://dx.doi.org/10.1080/00031305.2016.1154108 accessed 8/5/2017.
Replication file
The code to replicate Figures 2-4 is available at http://dx.doi.org/10.7910/DVN/C6QTF2. Figure 1 is a reprint of a figure originally published in Esarey and Wu; the replication file for that publication is available at http://dx.doi.org/10.7910/DVN/2BF2HB.
Notes
- I thank Jeff Grim, Martin Kavka, Tim Salmon, and Mike Ward for helpful comments on a previous draft of this paper, particularly in regard to the effect of lowered α on junior scholars and the question of whether statistical significance should be required for publication.
-
Specifically, I measure
, where
is a statistically significant estimate.
-
Here, I measure
, where μβ is the mean of f(β).
- The points in this paragraph are similar to those made by Esarey and Sumner (2017, pp. 15–19).
-
For statistically correlated tests, the degree to which \tilde{\alpha}" src="https://s0.wp.com/latex.php?latex=%5Calpha+%3E+%5Ctilde%7B%5Calpha%7D&bg..." title="\alpha > \tilde{\alpha}"> is smaller; at the limit where all the hypothesis tests are perfectly correlated,
.
-
Correlated significance tests require the creation of a joint distribution τ on the right hand side of equation ([eq:power-gain-line-one]) and the determination of a critical value t⋆ such that
; while practically important, this analysis is not as demonstratively illuminating as the case of statistically independent tests.
- In a paper with Nathan Danneman (2015), I show that a simple, standardized approach could reduce the rate of false positives without harming our power to detect true positives (see Figure 4 in that paper). Failing this, I would prefer a statistical significance decision explicitly tied to expected replicability, which requires information about researchers’ propensity to test null hypotheses as well as their bias toward positive findings (Esarey and Liu 2017). These changes would increase the complexity and the number of researcher assumptions of a statistical assessment procedure relative to the NHST, but not (in my opinion) to a substantial degree.