By Justin Esarey
In a prior post on my personal blog, I argued that it is misleading to label matching procedures as causal inference procedures (in the Neyman-Rubin sense of the term). My basic argument was that the causal quality of these inferences depends on untested (and in some cases untestable) assumptions about the matching procedure itself. A regression model is also a “causal inference” model if various underlying assumptions are met, with one primary difference being that regression depends on linearity of the response surface while matching does not. Presumably, regression will be more efficient than matching if this assumption is correct, but less accurate if it is not.
So, if I don’t think that causal inferences come out of a particular research design or model, where do I think they come from?
Let’s step back for a moment. Research designs and statistical models are designed to allow us to surmount some barriers to causal inference. Presuming that our interest is in the effect of a treatment X on a response Y, we can easily make a long and far from comprehensive list of these barriers:
- endogeneity (Y causes X)
- spurious correlation (W causes Y and X)
- selection bias (only cases with certain values of Y, or with a certain relationship between X and Y, are in our sample)
- ecological inference problem (e.g., average X is correlated with average Y in aggregated units, but a different relationship exists at the individual level)
- unrepresentative sample (the relationship between X and Y in our study does not match the relationship in the population because the distribution of contextual factors Z in the sample does not match the population)
- external validity (contextual influences in the study environment do not match contextual influences on the population of interest)
- invalid or unreliable measurement
- chance produced a relationship between Y and X where no causal relationship exists
- model dependence (the statistical technique we use to fix the above overdetermines the estimate in misleading ways)
…and on and on. Many people consider the laboratory experiment to be the gold standard for causal inference because it easily overcomes many of these barriers. If I can bring a proper (e.g., random) sample of a target population into a laboratory, break them into two groups, apply a treatment to one and not the other, carefully control the conditions between the groups, and I observe some average response in the treatment group that I don’t observe in the control… well, that’s pretty good evidence that the treatment caused the response. Problems 1, 2, 3, 4, and 9 are nearly impossible by design.
But even in these rarefied conditions, there are caveats. Perhaps the relationship between treatment X and response Y depends on contextual factor Z, and in a live environment levels of Z are substantially different compared to the laboratory. Outside the lab, where these contexts are present, perhaps X does not cause Y–or even has the opposite effect! (This is the heart of an external validity critique, #6.)
Research designs and statistical models usually face tradeoffs in how they address these barriers to causal inference. For example, a 2SLS model designed to fix an endogeneity problem with an instrumental variable hopes to fix problem 1, but increases the risk of problems of 7 or 8 (by requiring an accurate instrument, and imposing additional structural requirements via the relationship of instrument to X to Y). In the lab experiment above, we reduced problems 1-4 and 9 at the expense of problem 6 (and still must worry about 5, 7, and 8 despite the design).
Let’s index every potential inferential problem with 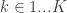
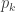

Thus, in some cases, 
total probability of a faulty inference =

If the events aren’t mutually exclusive but are independent, we’d have to write something akin to:
total probability of a faulty inference =

But the same basic ideas to follow still apply.
Now, here’s the heart of my argument. For any particular study, making different research design choices changes the 
That’s great–there’s nothing wrong with that. But I believe it’s reasonable to suspect that, in most cases, even perfect design and model choices can’t get 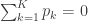
But there is a way to get small but non-zero probabilities down to zero: conduct a new study. Ideally, the
total probability that all inferences are flawed =

if all the probabilities are independent across the J studies, when faulty inferences are mutually exclusive inside of a single study. And this is very good, because 
total probability that all inferences are flawed =

and the same idea applies.
This also makes a second point clear: if a study has some design flaw that yields a somewhat high 

This is my basic reason for being less-than-enthusiastic about certain aspects of the credibility revolution in economics and political science; I am not quite a credibility counter-revolutionary, but maybe a Tory. It’s not because I don’t think that we shouldn’t strive to maximize the causal value of a particular study, what I would call 

In brief, I think that our causal inferences are most solid when they come from a collection of studies that tackle different aspects of a theory using different methods. These studies complement each others strengths, and consequently are greater than the sum of their parts. I also think that a collection of somewhat flawed studies can provide a better cut at causal inference than a single study that has fewer individual flaws, simply because we can never totally eliminate flaws but we can negate their importance with multiple studies.
Even worse, if we force every individual study to reach some minimum value of
[Update, 9/30/13 @ 4:31 PM]: some changes made to the structure of the probability of a faulty inference to correct errors and clarify points.
[Update, 10/1/13 @ 10:35 AM]: subscripts in some places changed to match rest of the paper.